缓存设计
需求
提升性能,内存缓存是关键,经典LRU根据访问频率更新,不能完全满足需求,通常业务更需要基于时间或事件触发更新。针对要求实时更新(用户信息、配置)和可以延迟更新(评论、动态列表)的数据,需要设计不同的缓存更新策略。
三种更新策略
- 超时删除(图中A)
即每个缓存key在put时记录有效期,当有效期到达时清理key(一般语言都有对应的库实现)
当get时,key存在则说明缓存有效,使用该缓存,否则查询db并更新缓存
- 事件触发(图中B)
即每次存储数据被修改时,发出事件通知
所有读数据的服务监听该事件通知(可通过redis或消息队列实现),收到修改事件时更新对应缓存key
- 检查触发(触发类似redis惰性删除)(图中C)
在get缓存数据时进行校验,缓存有效即使用,缓存无效查询db并更新
有效检查策略1:
数据添加版本号字段(可选用修改点的时间戳或数据的md5),db和缓存同时记录该版本号。
db更新的同时修改版本号,查询时缓存的版本号和db的做比较(从db拉去版本号效率远高于拉所有数据)
流程示意图:
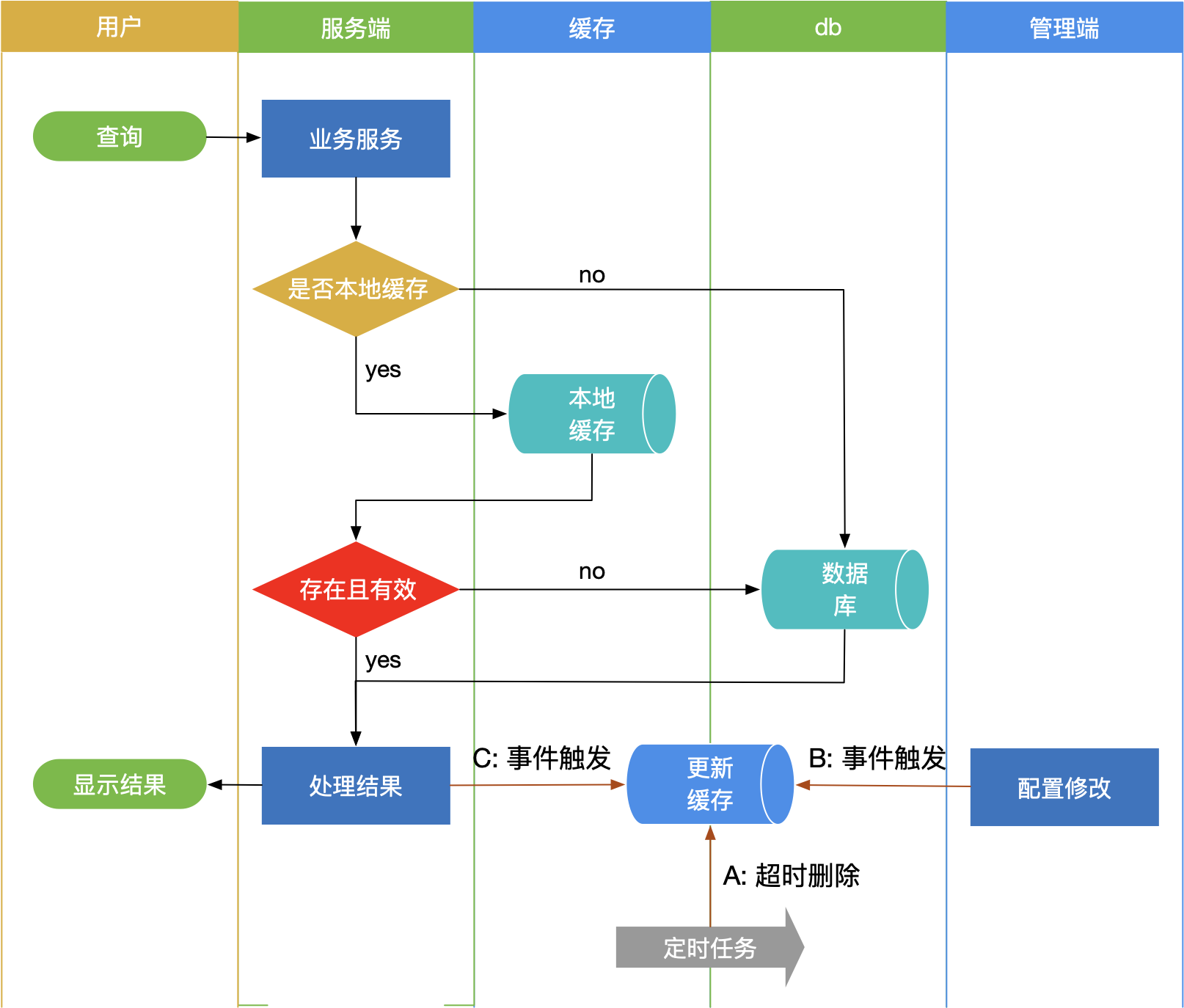
业务使用
- 用户信息:检查触发 + LRU 或 超时删除(设较大时间)=> 缓存实时更新 + 防内存泄露
- 配置数据:事件触发 + LRU 或 超时删除(设较大时间)=> 缓存实时更新 + 防内存泄露
- 动态、评论列表:超时删除(5s或10s)=> 缓存延迟更新
基于点击频率的LRU实现
x
package main
// LRUCache 结构体type LRUCache struct { size int capacity int cache map[int]*DLinkedNode head, tail *DLinkedNode}
type DLinkedNode struct { key, value int prev, next *DLinkedNode}
func initDLinkedNode(key, value int) *DLinkedNode { return &DLinkedNode{ key: key, value: value, }}
func NewLRUCache(capacity int) LRUCache { l := LRUCache{ cache: map[int]*DLinkedNode{}, head: initDLinkedNode(0, 0), tail: initDLinkedNode(0, 0), capacity: capacity, } l.head.next = l.tail l.tail.prev = l.head return l}
func (lru *LRUCache) Get(key int) int { if _, ok := lru.cache[key]; !ok { return -1 } node := lru.cache[key] lru.moveToHead(node) return node.value}
func (lru *LRUCache) Put(key int, value int) { if _, ok := lru.cache[key]; !ok { node := initDLinkedNode(key, value) lru.cache[key] = node lru.addToHead(node) lru.size++ if lru.size > lru.capacity { removed := lru.removeTail() delete(lru.cache, removed.key) lru.size-- } } else { node := lru.cache[key] node.value = value lru.moveToHead(node) }}
func (lru *LRUCache) addToHead(node *DLinkedNode) { node.prev = lru.head node.next = lru.head.next lru.head.next.prev = node lru.head.next = node}
func (lru *LRUCache) removeNode(node *DLinkedNode) { node.prev.next = node.next node.next.prev = node.prev}
func (lru *LRUCache) moveToHead(node *DLinkedNode) { lru.removeNode(node) lru.addToHead(node)}
func (lru *LRUCache) removeTail() *DLinkedNode { node := lru.tail.prev lru.removeNode(node) return node}
func main() { lRUCache := NewLRUCache(2) lRUCache.Put(1, 1) // 缓存是 {1=1} //spew.Dump(lRUCache.cache) lRUCache.Put(2, 2) // 缓存是 {1=1, 2=2} //spew.Dump(lRUCache.cache) lRUCache.Get(1) // 返回 1 lRUCache.Put(3, 3) // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3} //spew.Dump(lRUCache.cache) lRUCache.Get(2) // 返回 -1 (未找到) lRUCache.Put(4, 4) // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3} //spew.Dump(lRUCache.cache) lRUCache.Get(1) // 返回 -1 (未找到) lRUCache.Get(3) // 返回 3 lRUCache.Get(4) // 返回 4}
布隆过滤器
选取合适的hash算法,将目标字符串映射到对应的比特位上
比如:
"baidu": 1、4、7
"tencent": 3、4、8
查询 google:
- 假设google通过hash: 1、5、8
- 5位置上时0,则说明: "google"不存在
查询app le:
- 假设apple通过hash:1、3、8
- 1、3、8位都是1,则说明:"apple"可能存在
注意: 传统的布隆过滤器并不支持删除操作
常见缓存问题
缓存穿透
缓存和数据库都没有的数据,被大量请求
解决方案:
- 增加业务层级的
Filter - 布隆过滤器
- 缓存空数据(可以设置较短过期时间,注意更新策略的设计)
缓存击穿
缓存突然失效了,这时候如果有大量用户请求该数据
解决方案:
- 热点数据,那么可以考虑设置永远不过期
- 数据为空时,设置互斥锁更新缓存,保证只有一次请求到db
缓存雪崩
大量的缓存的数据,在同一个时间点过期
解决方案:
- 热点数据,那么可以考虑设置永远不过期
- 打散缓存过期时间,比如采取随机数
- 多级缓存(注意更新策略的设计)